Phantom Conditioning Test Results
Testing conditioning strategies for WanPhantom Subject-to-Video model
Last Updated: 2025-08-19
Test Motivation
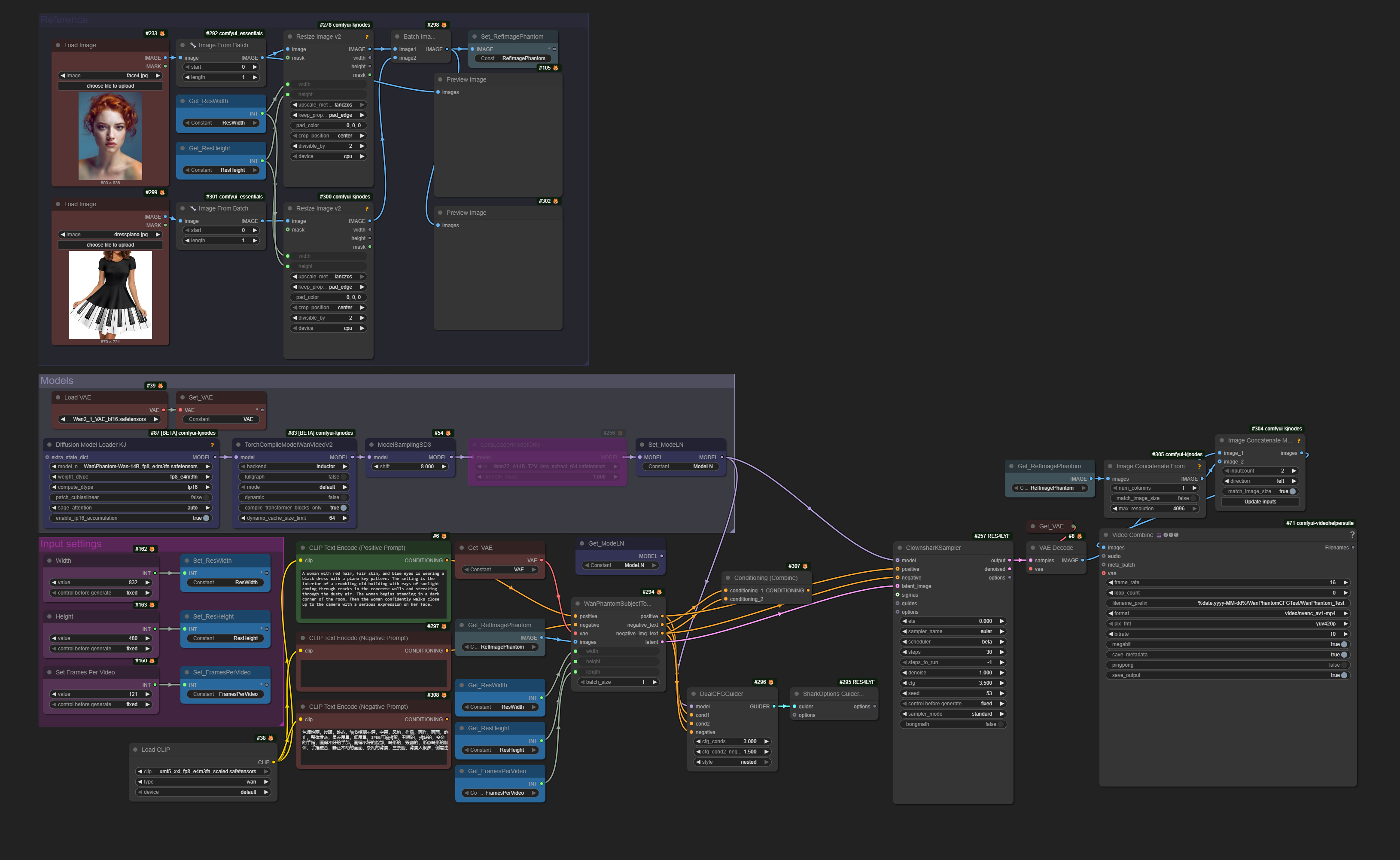
The WanPhantom Subject-to-Video model outputs three conditioning types: positive (text+image), negative_text (image-only with negative text), and negative_img_text (negative text with zeroed image embeddings). The paper describes a hierarchical dual-CFG approach using all three conditionings with specific weights (7.5 for text, 3.0 for image guidance).
The full ComfyUI node workflow used for these tests is embedded in the PNG image above.
These tests explore different conditioning combinations to find the optimal approach for balancing subject resemblance with prompt following. Testing includes the paper's recommended Dual CFG setup, standard CFG with various negative conditioning choices, and the empirically discovered ConditioningCombine approach that merges the two negative outputs.
All tests use the same reference image, prompt ("A woman with blue eyes..."), and seed for direct comparison. Generation speeds vary significantly between approaches due to the number of conditioning passes required.
More tests will be added including using quality and step-distill loras.